R-CNN 系列模型总结
Introduction
相比于分类,目标检测不仅仅要确定物体是什么,还要确定其在哪里;分类通常是一张影像获得一个类别,而检测则要找出影像中存在的多个物体,并确定其类别。因此,目标检测的两大任务:1.Object localization 2.Object classification。
基于深度学习的方法在最近5年来取得了显著的效果。本文将介绍深度学习在目标检测领域的开篇之作:RCNN(Region-based Convolutional Neural Network)及其后续版本Fast R-CNN、Faster R-CNN。
R-CNN
论文标题:Rich feature hierarchies for accurate object detection and semantic segmentation
论文地址:传送门
通过神经网络(AlexNet)提取丰富的、层次化的影像特征,R-CNN取得了显著的成绩,相比于传统方法,其精度提高了将近30%,达到了53.3%。
其网络示意图如下所示:
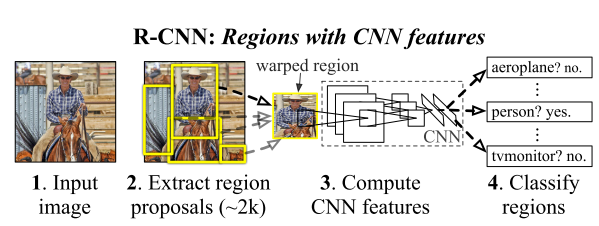
R-CNN的基本流程:
- 对于每幅输入影像,使用Selective Search(fast mode)方法提取将近2000个region proposals
- 对region proposals外包围一个固定大小的bounding box,使其具有固定的尺寸
- 将变换后的region影像块输入到预训练的CNN(AlexNet)当中,提取影像特征
- 将特征展开后,输入到多分类SVMs中,进行分类
Fast R-CNN
论文标题:Fast R-CNN
论文地址:传送门
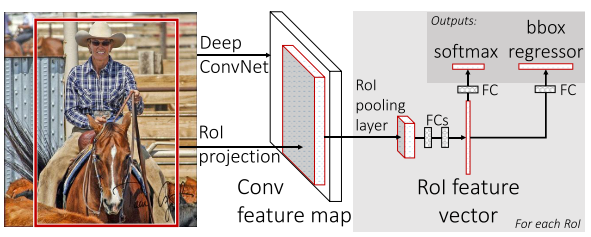
相比于R-CNN,Fast R-CNN依然保留了Selective Search方法提取Region proposals,但在使用CNN进行特征提取时做了一些改变:
- 相比于之前对每个ROI提取一次特征,直接对整张影像提取特征,使所有ROI共享特征,减少了特征提取所需的时间。即:CNN对整张影像提取特征,然后将不同的ROI映射到特征图上不同的位置,并将其作为ROI的特征图。
- Backbone更换为VGG16
同时在R-CNN中,不同大小的ROI仅仅是Warp了一个Bounding box,而在Fast R-CNN中,加入了一个ROI Pooling层,从而解决了尺度大小不同的问题,具体来说:
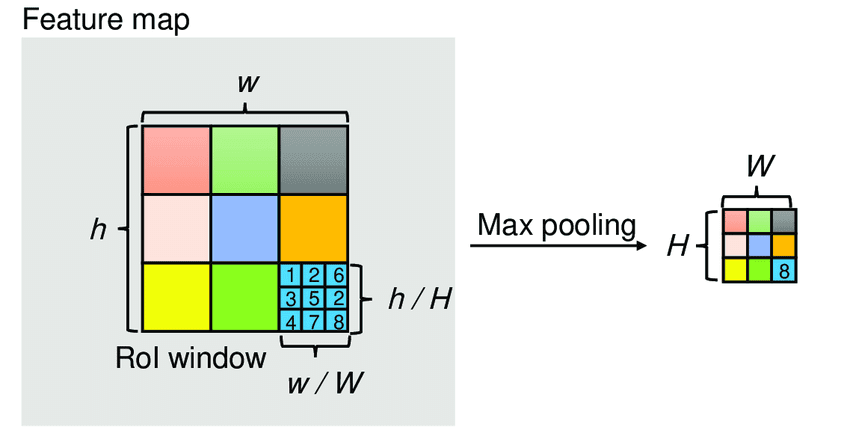
- ROI Pooling示意图如下所示,对于一幅$h \times w$的影像,为了使其经过pooling后得到固定大小的输出,将其分成一个个小网格,每个网格的大小为$(h/H,w/W)$,接着对每个网格进行Max Pooling,从而就得到了大小为$H \times W$ 的输出。
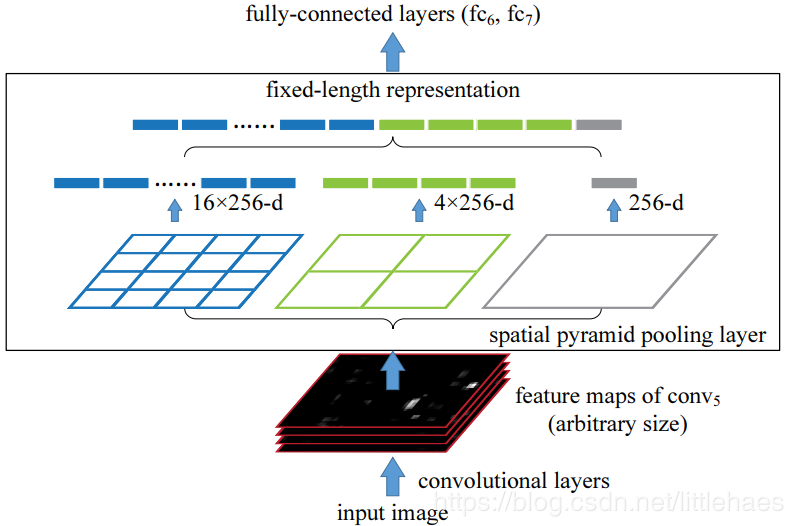
2.经过ROI Pooling,不同大小的Region proposals变成了大小相同的矩阵,接着将其展开为固定大小的向量(如256-d)
Fast R-CNN也更换了分类器,从R-CNN的SVMs变为多个Fully connected layer+SoftMax Classifier,论文中也提到,使用softmax会有一定的精度提升,同时说明了One-shot模型比Multi-stage效果要好,也注意到Softmax是不同类之间的竞争,而不像SVM的一各类别与其他类别分类。
另外在网络训练时,提出Multi-task Loss,即$loss_{cls}$和$loss_{loc}$。其中
$$L(p,u,t^u,v) = L_{cls} + \lambda [u \ge 1] L_{loc0}(t^u,v)$$
其中分类误差使用的是log loss,即$$L_{cls}(p,u) = - log p_u$$,而定位误差使用的是smooth L1 Loss,即
$$L_{loc}(t^u,v) = \sum_{i \in{x,y,w,h}}smooth(t_i^u-v_i)$$
其中$p$为预测标签,$u$为Ground truth,$\lambda$为两个Loss间的平衡系数,$u$用来区分背景和物体,$t^u = (x^u,y^u,w^u,h^u)$,代表物体预测Bounding box与Groung truth之间的偏移量。
总结来说,Fast R-CNN的基本流程:
- 使用Selective Search提取Region Proposals
- 使用CNN提出特征,使用ROI取出其对应的特征图区域
- 将所有的特征图送入ROI Pooling层,接着拼接成固定长度的向量
- 使用两个平行的模块,一个用于物体类别分类,一个用于Bounding box定位
Faster R-CNN
论文标题:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
论文地址:传送门
相比于R-CNN、Fast R-CNN,Faster R-CNN的最大突破在于采用RPN(Region Proposal Network)提取Region Proposal,而不是传统的Selective Search方法,从而使RPN和Detection Network共享特征图的特征,使得产生ROI的时间进一步缩短,同时使得精度进一步提升。
首先需要着重介绍RPN的概念。
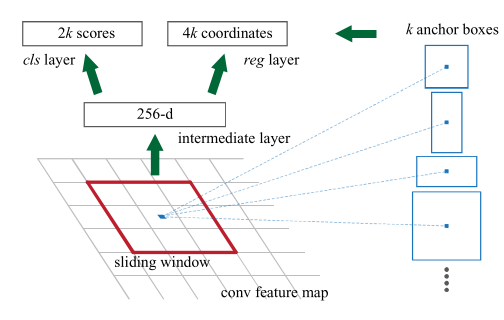
其基本流程如下:
- 使用预训练的CNN网络得到大小为$(N \times W \times H)$的特征图
- 使用$(3 \times 3)$的卷积核对特征图进行卷积,得到256维$(256 \times W \times H)$的特征图
- 对于cls layer,使用$(1 \times 1)$卷积,得到$(2 \times k \times H \times W)$的特征图,对于reg layer,使用$(1 \times 1)$卷积,得到$(4 \times k \times H \times W)$的特征图,其中$k$为anchor box的数量,文中设定其为$k=9$。
使用另一张图可能更好的说明RPN的基本流程:
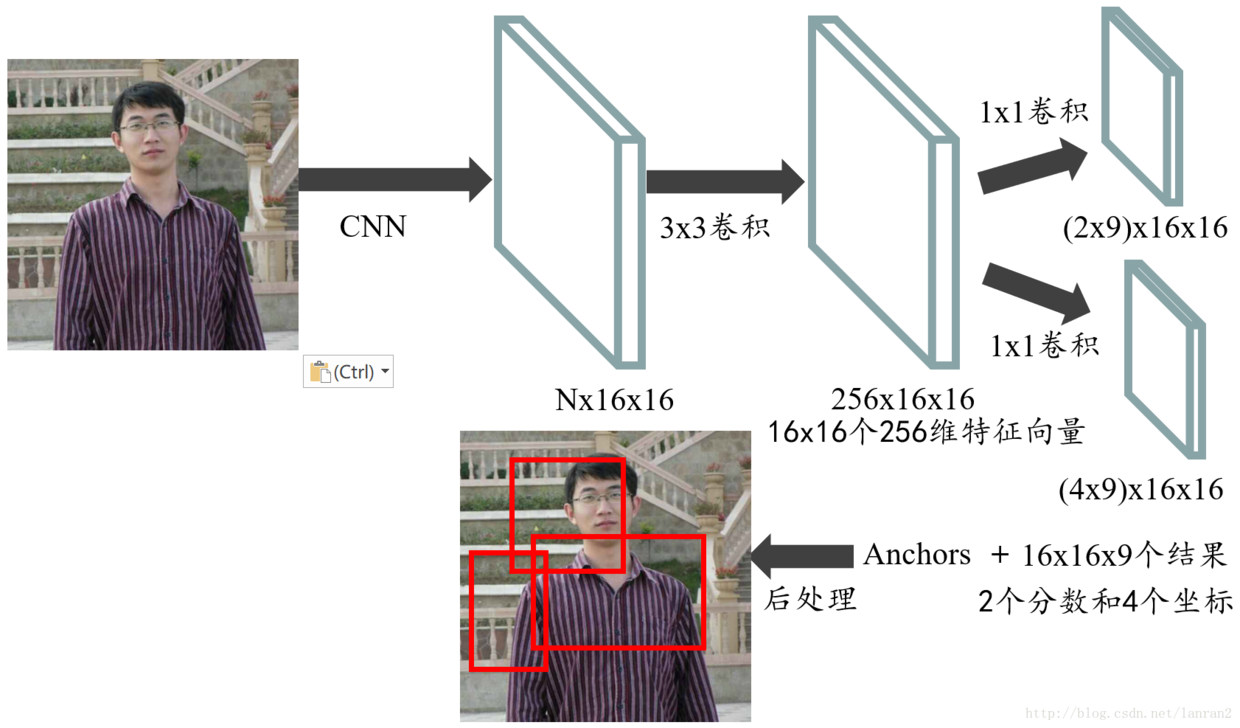
比较特殊的是Faster R-CNN的训练。为了能够使Region Proposal和Object Detection共享卷积网络的特征,FRCN使用了特殊的训练方法。如果单独训练RPN和Fast R-CNN,则它们均会改变CNN层的权重。由于Fast R-CNN部分的训练需要固定的Object Porposal,因此他们两者不能同时开始训练。其训练步骤如下:
- 单独训练RPN
- 使用RPN产生的Region Proposal训练Fast R-CNN
- 使用Detection网络初始化RPN的训练,同时固定共享(share)的卷积层,只训练RPN独有的层
- 固定共享的卷积层,训练Fast R-CNN
因此总结来说,Faster R-CNN = Fast R-CNN + RPN。
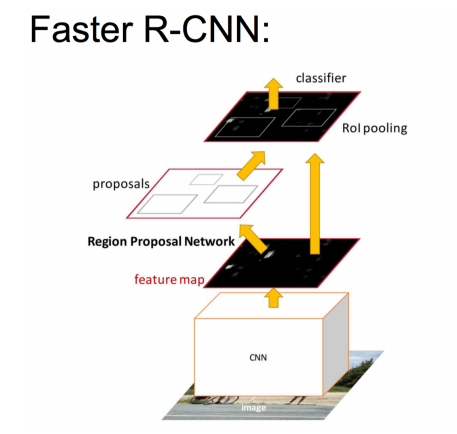
Summary
从R-CNN到Fast R-CNN到Faster R-CNN,其不断减少stage,从multi-stage到one-shot
- R-CNN:Selective Search + CNN + SVM
- Fast R-CNN:Selective Search + CNN + ROI Pooling
- Faster R-CNN:RPN + CNN + ROI Pooling
参考文献
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!