FSAF:Feature Selective Anchor-Free Module for Single-Shot Object Detection
论文名称:Feature Selective Anchor-Free Module for Single-Shot Object Detection
论文地址:传送门
Abstract
本文提出了Feature Selective Anchor-free(FSAF)模块,它是一个用于一阶段检测器的极其简单的building block,可以加入到任何有FPN结构的模型当中。
FSAF主要解决anchor-based+FPN当中的两个问题:
- 启发式特征选择(heuristic-guided feature selection)
- 基于重叠面积的样本选择(ovelap-based anchor saampling)
FSAF模块基本的概念是应用在训练过程中的多层anchor-free分支。具体来说,一个anchor-free分支被应用在FPN的每一个层上。在训练过程中,我们动态的将实例(instance)分配给最适合的特征层。在测试时,FSAF可以和anchor-based分支联合输出预测结果。
试验结果表明,FSAF在COCO数据集上比anchor-based的检测器精度更高且速度更快。在和anchor-based分支一起工作时,FSAF可以稳健的提升Retinanet的baseline。最后,加入FSAF的最好的模型在COCO上可以达到44.6%的mAP。
Introduction
目标检测当中一个很有挑战性的问题就是尺度差异(scale variation)。为了实现尺度不变,SOTA的方法都采用FPN的结构。如下图所示,可以看到40和50被分在了同一层,而60被分在另一层。
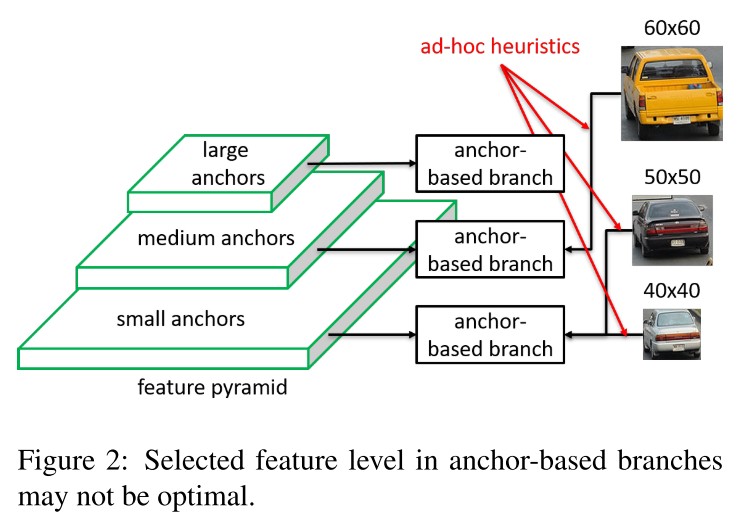
而FSAF出发点就是让每个实例选择最好的feature level来优化整个网络。具体来说,在anchor-based detector当中,每个实例的分配是人为设计的,而我们通过FSAF可以去学习这些参数,从而将实例分配到最适合的feature level上。如下图所示。
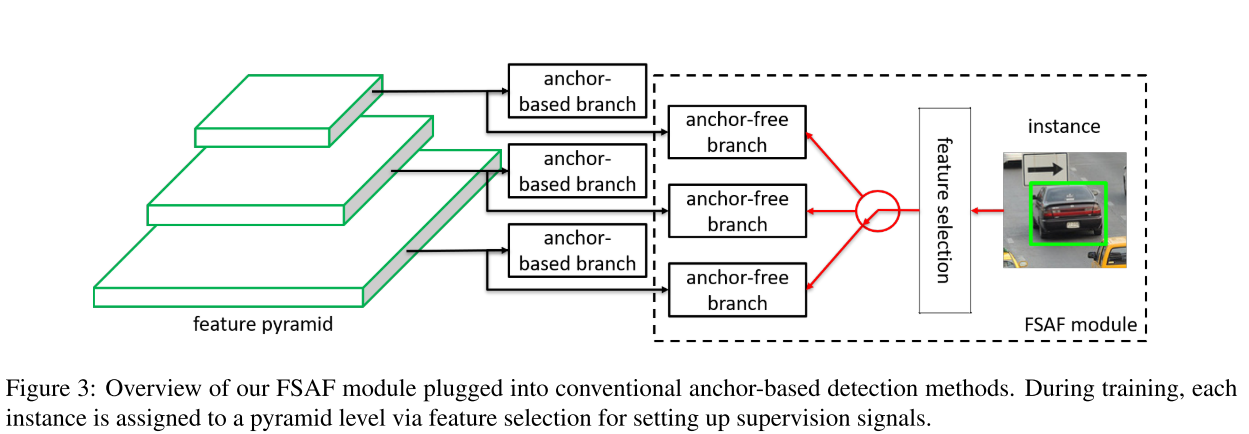
在FPN的每个level上都有一个anchor-free的分支,每个分支包含一个分类子网络和回归子网络。一个实例被分配到anchor-free的每一个分支,在训练的过程中,我们动态的选择最适合这个实例的level,而不是简单的根据其bounding box分配到一个层。在测试时,FSAF可以和anchor-based分支一起预测。
此外,FSAF也可以被应用在使用FPN的Single-Stage detector当中。
Feature Selective Anchor-Free Module
Network Architecture
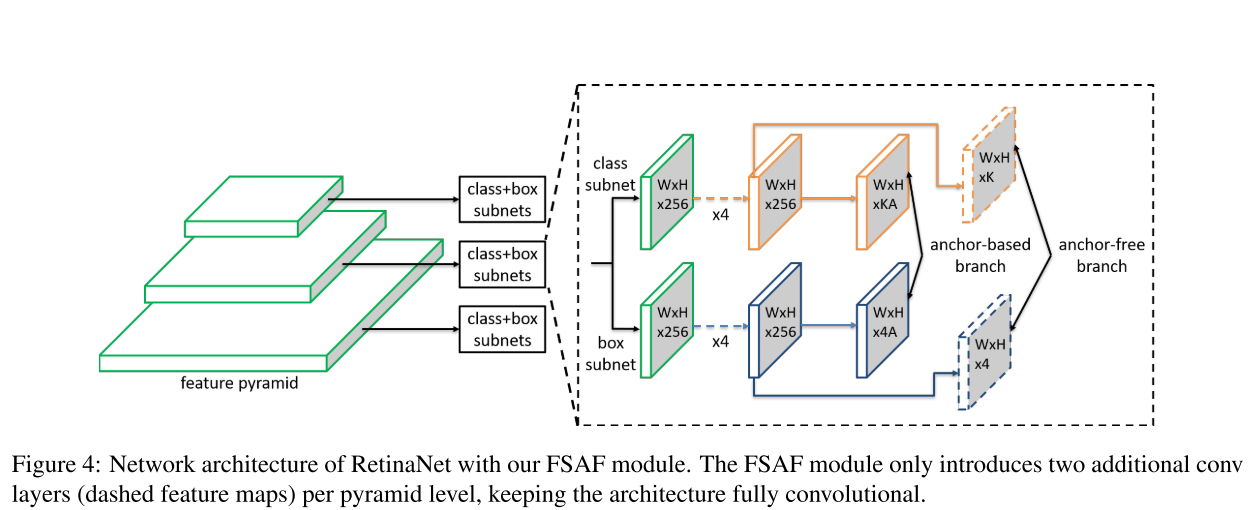
RetinaNet和FSAF的网络结构如上图所示。可以看出,FSAF的结构极其简单。RetinaNet可以看作一个backbone和两个分支网络,一个cls,一个reg。而FSAF则是在cls和reg分支上分别添加一个anchor-free分支,同样的,在cls上的分支负责分类,在reg上的分支负责回归。
具体来说,FSAF在每个feature level引入了两个额外的卷积层。每个卷积层都是通过$3 \times 3$的卷积核实现的,对于cls分支则有K个卷积核,其中K为数据集类别;对于reg分支,则有4个卷积核,对应四个坐标值。
Ground-truth and Loss
对于一个实例,我们知道它的类别$k$和坐标$b=[x,y,w,h]$。
$b_p^l=[x_p^l,y_p^l,w_p^l,h_p^l]$ 是$b$在特征金字塔的$l$层$P_l$上的映射。
$b_e^l=[x_e^l,y_e^l,w_e^l,h_e^l]$ 是有效框,表示一个框的中心位置,如下图的白色区域。
$b_i^l=[x_i^l,y_i^l,w_i^l,h_i^l]$ 是忽略框,如下图灰色区域。
对于一个框内其他部分则被作为负样本,其值都是0.
在本文中,设定了有效框的范围为0.2,忽略框的范围为0.5.
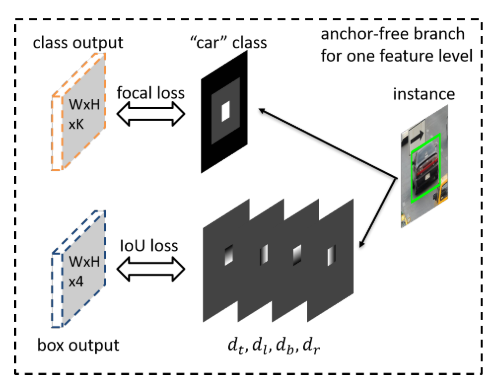
Classification Output
cls分支的输出是K个分类图,每个图对应一个类别。我们对ground truth map有以下定义:
- 有效框(上图白色区域)的值为1
- 忽略框(灰色区域)的值不会回传到网络当中
- 相邻特征图的忽略框也是此特征图的忽略区域。
loss选择Focal Loss,cls总的loss是所有有效框的和,并使用像素总数进行normalize。
Box Regression Output
回归的ground truth是与类别无关的4个offset maps。对于有效框内的一个像素点$(i,j)$,我们定义$d_{i,j}^l=[d_{t_{i,j}}^l,d_{l_{i,j}}^l,d_{r_{i,j}}^l,d_{b_{i,j}}^l ]$,分别表示点到框四边的距离。有效框外的区域被忽略。loss选择IOU Loss,总的回归Loss所有有效框的平均值。
在inference的时候,可以直接解码出bbox和class,每个框的分数可以从classification map中得出。
Online Feature Selection
FSAF的出发点就是通过学习选择出最适合每一个实例的特征层,而不是根据框的大小直接分配。对于一个实例$I$,我们定义其分类Loss和回归Loss分别是$L_{FL}^I(l)$和$L_{IoU}^I(I)$。($l$表示FPN中的$l$层)
$$\begin{aligned} L_{F L}^{I}(l) &=\frac{1}{N\left(b_{e}^{l}\right)} \sum_{i, j \in b_{e}^{l}} F L(l, i, j) \ L_{I o U}^{I}(l) &=\frac{1}{N\left(b_{e}^{l}\right)} \sum_{i, j \in b_{e}^{l}} L_{IoU}(l, i, j) \end{aligned}$$
其中$N(b_e^l)$表示$b_e^l$中的像素总数。
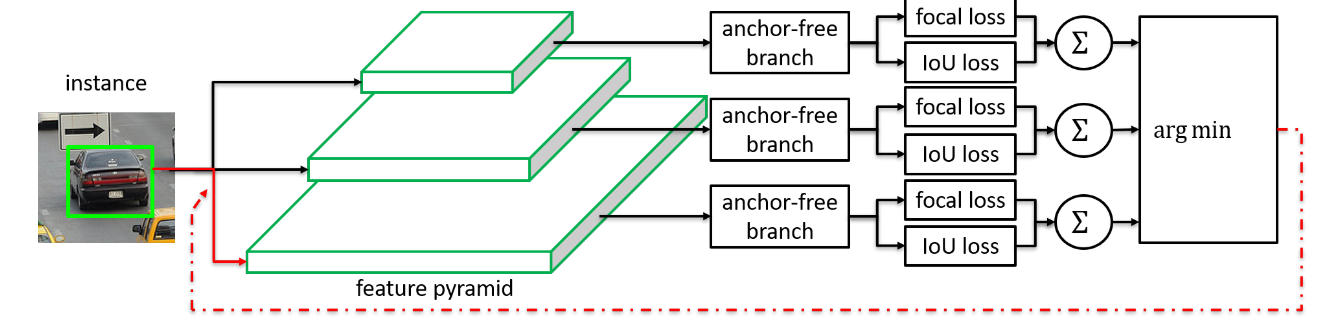
上图表示在线特征选取的过程。每个实例都通过所有feature level的anchor-free分支,然后计算每一层总的Loss,最后将实例分配到Loss最小的那一层。
$$l^{*}=argmin_{l} (L_{F L}^{I}(l)+L_{I o U}^{I}(l))$$
对于一个训练的batch,features负责的实例被更新。其目的是选择最适合这个实例的特征。通过训练,我们可以进一步提高其下界(也就是说,无论其被分配到哪个层,都有较好的检测效果)。在测试的时候,我们不需要选择特征,因为最适合的特征层可以输出较高的置信度。
有个问题:刚开始训练的时候,某个实例被分配的特征层应该会不断地移动吧?
Joint Inference and Training
FSAF可以和RetinaNet一起工作。在Inference时,FSAF分支的输出结果也可以解码出bbox,我们经过置信度0.05后,在每一个feature level上选择1k个top-scoring locations,然后和anchor-based branch一起使用NMS进行筛选。
优化: 整个网络的Loss包括anchor-based的和anchor-free的。
$$
L=L^{a b}+\lambda\left(L_{c l s}^{a f}+L_{r e g}^{a f}\right)
$$
本文将$\lambda$设置为0.5。整个网络使用SGD,在8块GPU上训练,每个GPU两张图像。
Experiments
整个实验在COCO上进行,训练数据是COCO trainval35k,包含来自train的80k图像,和来自val的35k图像,测试时使用minival的5k图像,在比较精度时,使用的是test-dev。
Ablation Studies
Anchor Free branches are necessary. FSAF更擅长哪些具有挑战的物体,如小物体,特别瘦长的物体及那些不能被anchor boxes覆盖的物体。
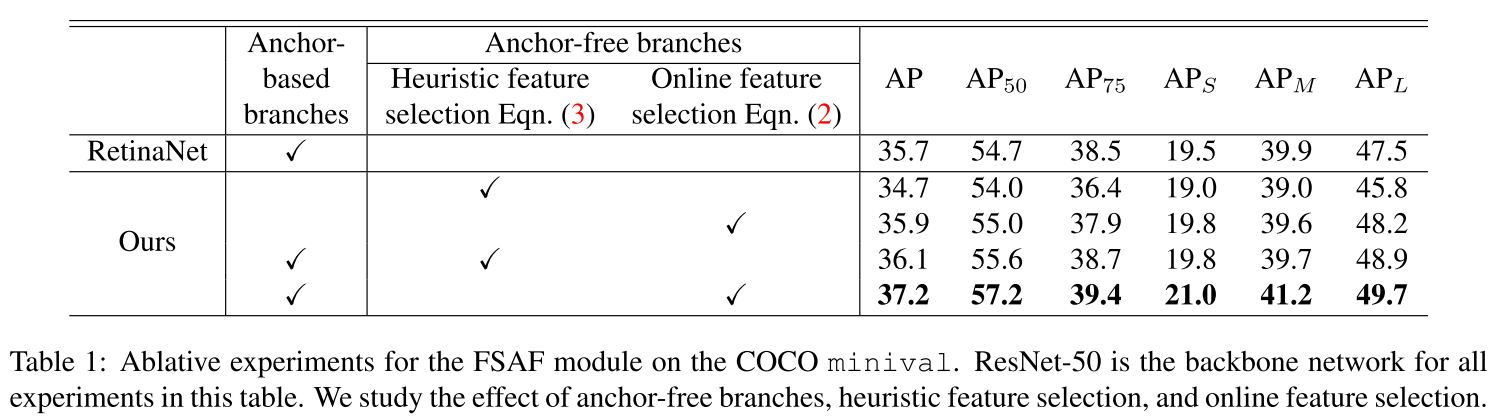
Online feature selection is essential. 可以看到FSAF也遵循大的目标分配在高层,小的目标分配在底层的规则,然而FSAF和RetinaNet检测的也有些许的不同。

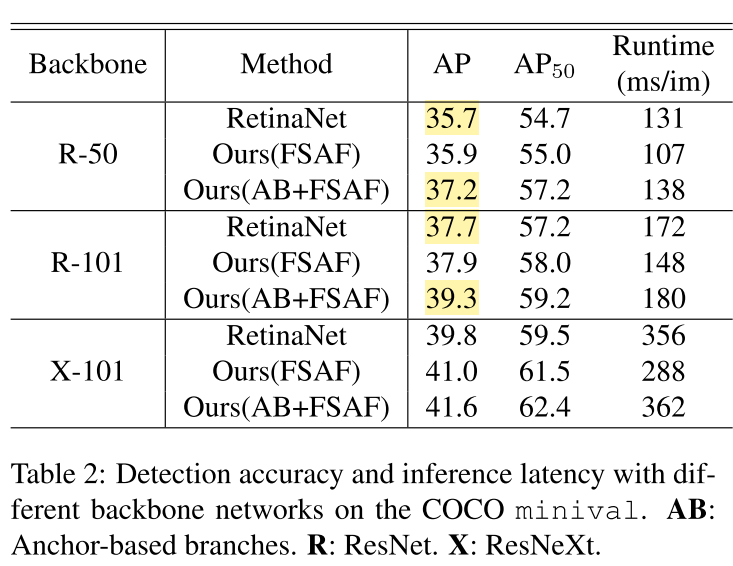
FSAF module is robust and efficient.
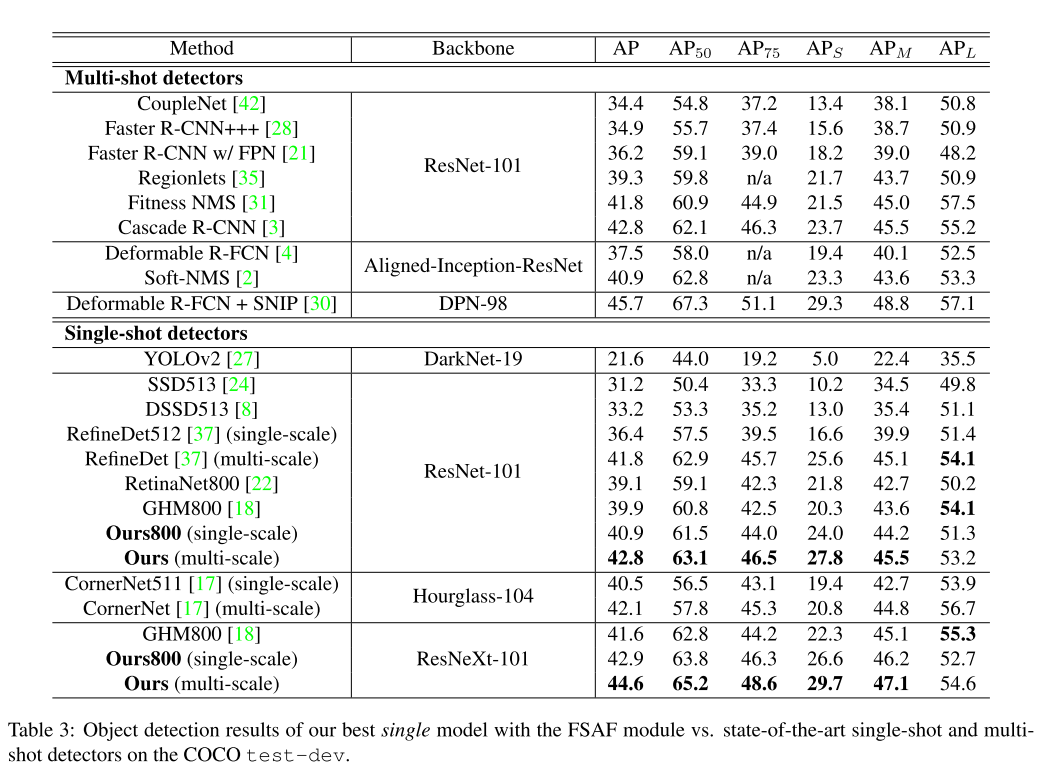
Comparison to State of the Art
Conclusion
FSAF在FPN特征选层这个问题上做了深入的探讨,并通过加入很小的head,实现了动态的分配实例,而不是根据其尺寸进行分配,因而进一步提升了精度,却没有引入多少计算量。
另外刚好最近读了FCOS,发现两者还是有很大的相似之处。不同的是FSAF是将FCN加入到RetinaNet当中,而FCOS是加入center-ness,直接使用FCN。
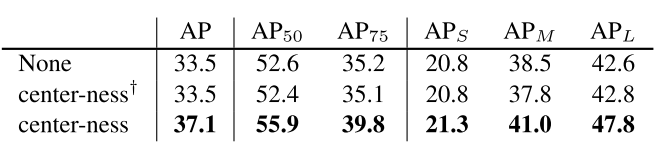
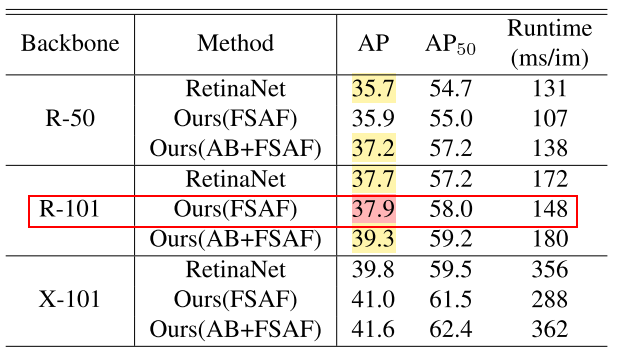

有没有觉得,FCOS比FSAF高的那3.6(41.5-37.9)是从center-ness中来的?
接下来我也会实验一下,看看FSAF+center-ness的效果怎么样。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!