RetinaNet模型总结
论文名称:Focal Loss for Dense Object Detection
论文地址:传送门
Introduction
目前在目标检测领域,two-stage detector(如R-CNN系列)通常能取得较好的精度,但速度较慢;而one-stage detector(如SSD、YOLO)通常速度比较快,但精度会较低。如何保持检测速度的同时,能够提高one-stage检测精度,作者指出类别不平衡性是主要原因,因此作者提出了Focal Loss来解决类别不平衡问题,使本文提出的RetinaNet也能实现较高的精度。
类别不平衡性通常会导致两个问题:
- 许多易分类的负样本对训练没有什么贡献,导致训练较为低效。
- 这些Negetive的样本影响模型的训练,导致模型整体学习方向偏离。
而在two-stage detector中,通常有两种解决方案:
- 使用两个阶段进行递归(cascade)。在多阶段cascade时,可以逐渐筛去easy negetives,使得样本之间平衡。
- 选择mnibatch时,有针对的选择正负样本。如正:负=1:3。
Focal Loss
为了解决正负样本间的极度不平衡性,作者提出了Focal Loss。
通常情况下,对于两分类问题我们使用Cross Entropy Loss,即:
$$CE(p,y)=\begin{cases}
-log§, & \mbox{if } \quad y = 1 \
-log(1-p), & otherwise.
\end{cases}$$
其中y为Ground truth label,$p \in [0,1]$为预测结果,为了方便描述,CE也可以表示为:
$$p_t=\begin{cases}
p & \mbox{if} \quad y=1\
1-p & otherwise
\end{cases}
$$
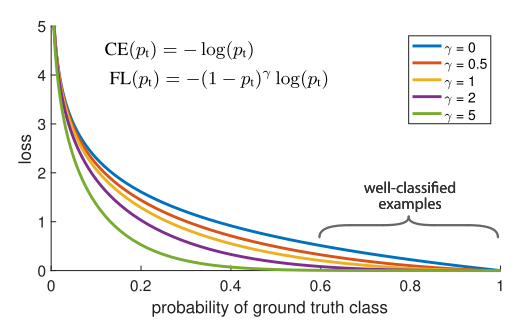
此时有$CE(p,y)=CE(p_t)=-log(p_t)$,对应下图曲线上的蓝色曲线。可以看到,即使$p \ge 0.8$,仍有很大的loss。
这种损失的一个显着特征是,即使很容易分类(pt≫ .5)的例子,其损失也具有不小的幅度。 如果将大量简单的例子相加,这些小的损耗值可能会导致错误的类别。
为了解决这个问题,作者提出了Balanced Cross Entropy,即:
$$CE(p_t)=- \alpha_t log(p_t)$$
为了降低易分类目标(easy examples)的权重,使模型在训练时更加专注于难分类样本(hard exmaples),作者提出了Focal Loss,不同$\gamma$对应的图像如上图所示。
$$FL(p_t)=-(1-p_t)^{\gamma}log(p_t)$$
使用Focal Loss之后,大量易分的negtives的loss就减小了,从而使模型更加专注于难以区分的目标。
Focal Loss还有另一种形式:
$$FL(p_t)=-\alpha_t(1-p_t)^{\gamma}log(p_t)$$
本文实验采用的即时此种形式。
RetinaNet Detector
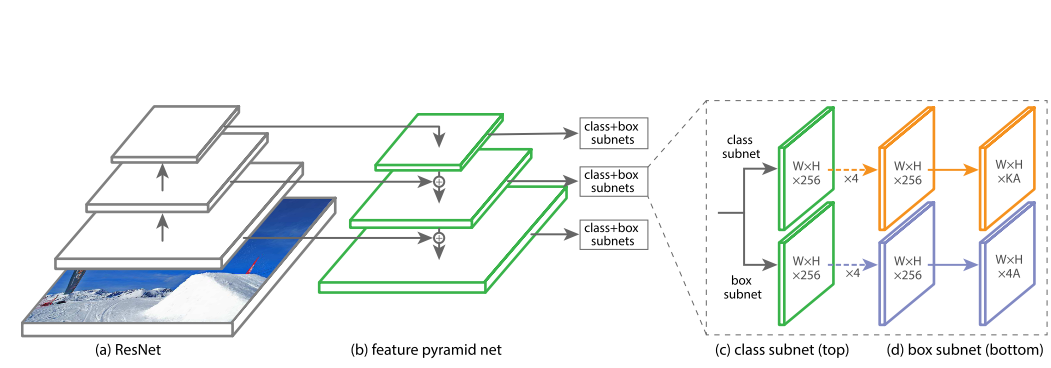
- ReNet作为backbone
- 采用FPN(Feature Pyramid Network)进行不同scale的采样。
- 对于每个scale level,都有一个class net和box net。
- 将最终预测的anchor进行merge,使用NMS进行筛选。
其中,FPN使用的的是$P_3$到$P_7$,$P_3 \dots P_5 \rightarrow C_3 \dots C_5$,而$P_6$是对$C_5$进行卷积得到的,$P_7$是通过对$C_6$卷积得到的。
对于每个level,不仅仅是从$32^2$到$512^2$的大小,还有${2^0,2^{1/3},2^{2/3}}$三个尺寸,每个尺寸都有三个ratio:${1:2,1:1,2:1}$,即每个level都有9个anchor box。对于每个anchor box,都单独预测K个class,即总共需要$KA$个值。
对于box net,则简单的预测$4A$个值,对应着A个anchor box的坐标。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!