YOLO系列模型总结
YOLO v1
论文名称:You Only Look Once: Unified, Real-Time Object Detection
论文地址:传送门
Introduction
以往的目标检测算法(尤其是R-CNN系列)将目标检测问题归结为分类问题,即先寻找目标可能存在的区域(Bounding box),然后对这些Box分类,从而确定目标。Yolo则将目标检测问题转换为一个回归问题(Regreesion problem),直接预测出boudning box和相关的类别信息。Yolo是一个可以端到端训练的single network,它不需要单独的搜索Region Proposals,也不需要单独的Classifier,因此其检测速度特别快,Yolo可以达到45FPS,而Fast Yolo可以达到155FPS。Yolo对背景的识别效果较好,且有一定的迁移性,可以识别一般问题(如Artwork),但是Yolo最大的问题是对小目标的检测不准确。
Yolo目标检测的基本流程如下图所示:

- 将图像resize到$448 \times 448$
- 使用单一的网络进行训练
- 设置阈值得出最终的检测结果
Unified Detection
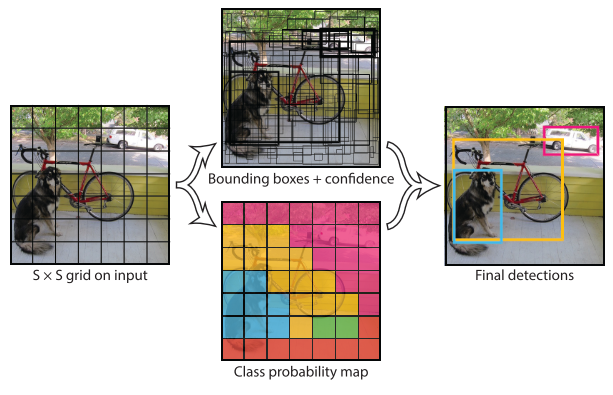
模型设计的细节:
- 将一个大小为$m \times n$的图像划分成$S \times S$的网格,如果一个Object的中心在某个网格,则这个网格负责这个物体的检测
- 每一网格预测$B$个Bounding Box和这个Box的置信度。置信度表示有多大的把握说明这个Box包含物体及其预测的有多准确,其可表示为$Pr(Object) * IOU_{pred}^{true}$。因此每个Bounding Box包含5个参数:$x,y,w,h$和置信度,$(x,y)$表示Box中心坐标相对于网格边缘的位置,宽和高则是相对于整个图像,置信度表示预测框和真实框之间的关系。
- 同时每个网格预测$C$个类别概率:$Pr(Class_i|Object)$。Yolo不是对每一个Bounding box预测类别概率,而是仅对一个网格预测概率。
- 因此对于一幅影像,其被划分为$S \times S$个网格,每个网格预测$B$个Box及其置信度,则最终的预测被编码为大小为$S \times S \times (B * 5 + C)$的向量
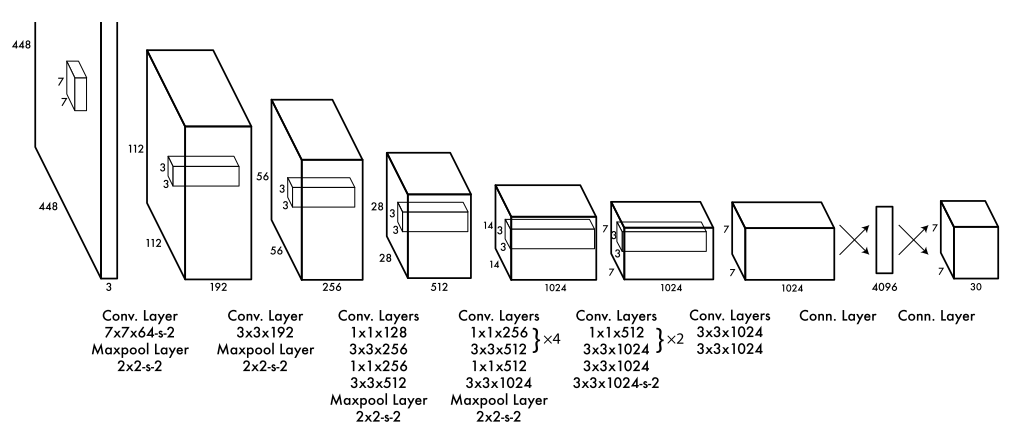
Network Design
Summary
YOLO将检测转换为一个回归问题,通过对图像划分网格,可以快速的检测物体,是Real Time Detection的开创性工作。
YOLO v2
论文名称:YOLO9000: Better, Faster, Stronger
论文地址:传送门
TODO
YOLO v3
论文名称:YOLOv3: An Incremental Improvement
论文地址:传送门
Introduction
YOLO v3在之前YOLO的版本上做了一些调整,使其检测精度有所提高,对小物体的识别精度得到提升,但同时由于其更换了backbone网络,增加了运行的时间。
YOLO v3使用了新的网络:DarkNet53作为底层网络,在网络中加入了Residual Block,同时借鉴了SSD的多层特征,利用不同层的特征图检测大小不同的目标,从而提升了小目标的检测精度。
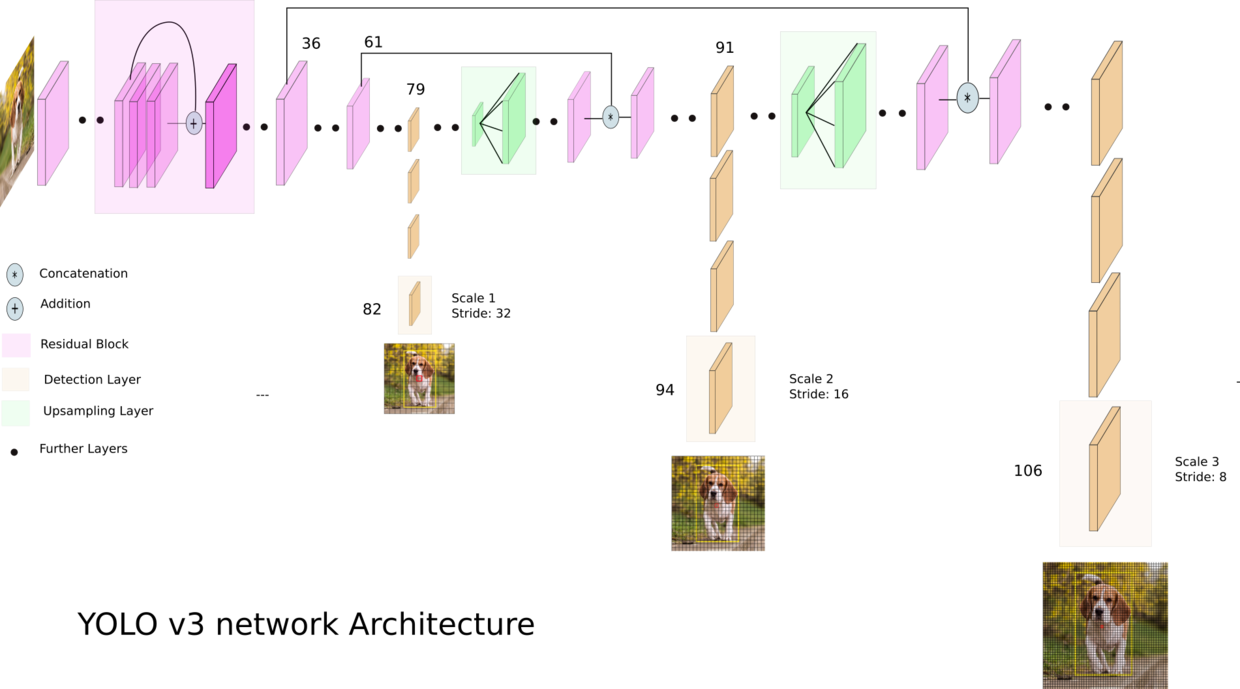
Detection at three Scales
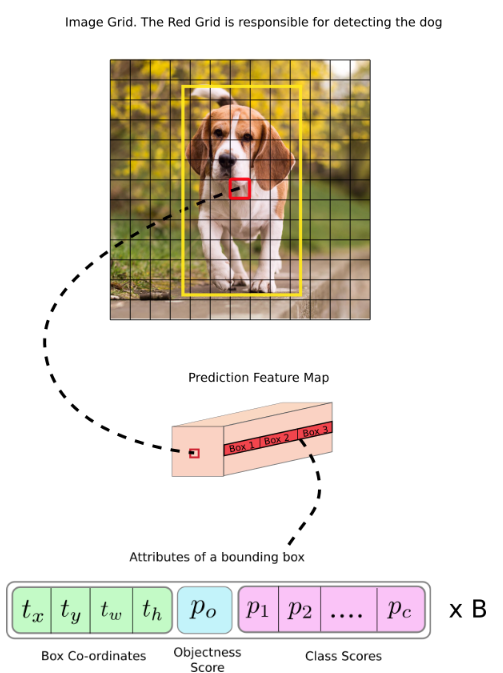
YOLO v3也采用了residual connections,upsampling,输出其中的三个特征图作为三个不同尺度的检测。对于每一个特征图,其使用形状为$1 \times 1 \times (B \times (5 + C))$的卷积核。其中B为Bounding box的数量,5代表$(x,y,w,h)$和一个物体置信度,$C$代表数据的类别。这里与YOLO v1就有所不同,YOLO v1对每个网格仅预测一个cls。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!